data mining 1_2(importance of database /lr ML's objective function / 목적함수)
Data generation process란.
artificial situation의 예를 들어보자.
한 주사위 게임에서 x가 나오면 y = (x-7)^2 +1 만큼의 포인트를 준다고 가정하자.
우린 이런 상황에 대해서 data generation process(데이터 생성 과정)를 완벽히 알고 있다고 말할 수 있다.
위의 상황에서 우리는 x의 값만 알면 y값을 정확하게 예측할 수 있다.
또한 x가 나올 확률 (1/6)을 알기 때문에 P(x)에 대해서도 정확히 알 수 있다.
그리고 P(x)를 알기 때문에 새로운 데이터를 생성할 수도 있다.
하지만.!!!!!!!!!!!!!!!!!!!
머신러닝에서 우리는 데이터 생성 과정을 알 수 없다.
오직 train set을 가지고 estimate model or generated model을 근사하게 만들 수 있다.
The importance of databases
Given application environment에 대해서 충분히 다양한 데이터를 수집해서 모델을 학습시켜야 accuracy의 increase를 기대할 수 있다.
예를 들어보자. 정면 사진만으로 구성된 데이터를 가지고 모델을 학습시킨다고 가정하자. 과연 옆면의 얼굴이나, 위에서 촬영된 얼굴을 모델이 잘 예측할 수 있을까? 때문에 충분히 application environment를 파악하고 그에 맞는 db를 구하는 것은 매우 중요하다.
Relatively small size of database
Mnist dataset을 예로 들어, 한 object가 가질 수 있는 가질 수 있는 경우의 수는 2^784개 있다. (Mnist 28 * 28 size 사진 데이터이므로 28*28를 flatten하면 = 784개가 나오고 각 차원이 흑백(0,1)만을 domain으로 갖는다고 할 때 2^784 !
이 경우 차원의 저주를 설명했을 때 이야기했듯이. 한 sample은 2^784개 중 하나 위치하는 것이고 Mnist dataset의 경우 6만개의 샘플을 갖고 있기 때문에 6만/2^784. 6만개가 많아보이지만 상대적으로 보았을 때 굉장히 왜소한 크기라는 것을 알 수 있다.
그렇다면 이렇게 작은 사이즈의 db를 가지고 어떻게 좋은 performance를 만들어 낼 수 있을까?
다시 Mnist로 예를 들자면 2^784개의 공간 중에서 실제 actual data가 발생하는 공간은 매우 작다. 예를 들어. 숫자 2가
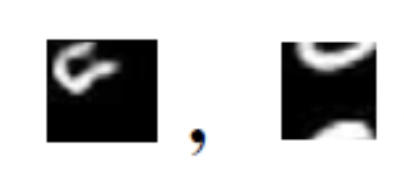
이런식으로 나타날 확률은 매우 적다고 할 수 있겠다. 그렇다면 이런 경우는 그냥 배제하고. 어차피 이런건 사람도 못맞춤

요런 데이터만을 가정할 수 있다고 해보자. 이를 mainfold를 가정한다고 한다. (assume mainfold)
이 assuming mainfold가 어떻게 이용되는지는 나중에 다루겠다.
Hyperspace over 4 dim's visualization.
4차원 이상의 공간은 한꺼번에 visualization하는 것이 불가능하다. 때문에
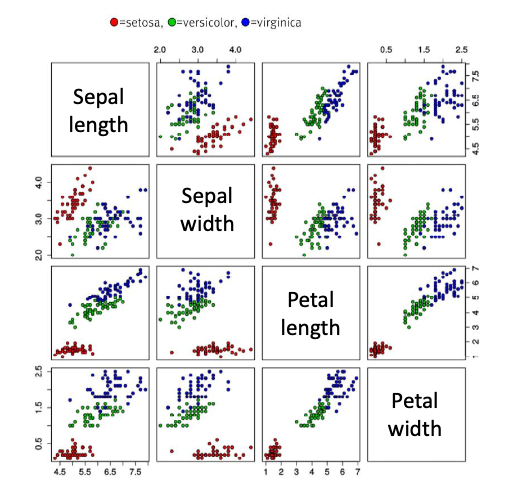
이렇게 2개씩 조합하여 여러 개의 그래프 그림을 함께 보는 방법과 고차원 공간을 저차원으로 변환하는 기법들이 있다.
Simple Example of ML
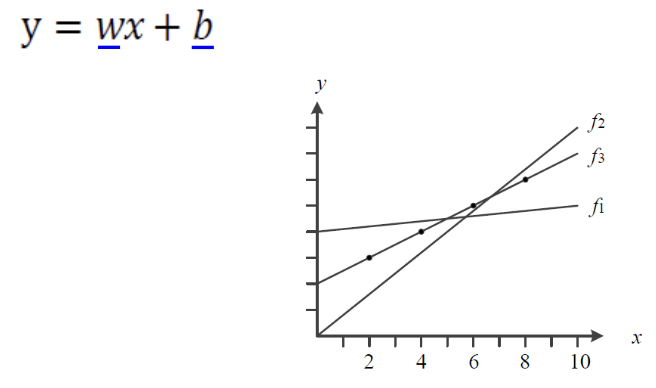
위와 같이 직선의 선형 모델이 있다. linear model의 경우 앞서 d+1개의 parameter를 갖는다고 했다.
때문에 위 모델은 w, b. 2개의 parameter를 갖는 모델이다.
- Objective function( Cost Function) / 목적함수(비용함수)
선형 모델의 경우 목적함수는 다음과 같다.
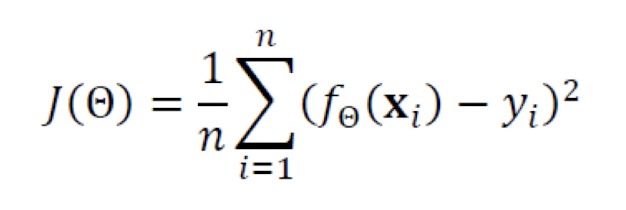
여기서 f_theta(x_i)는 theta번째 예측함수이고, y_i는 실제 i번 째 데이터에 대한 y 값이다. 이 말이 뭔 말이냐고 할 수 있다. 나중에 설명하겠다.
또한 위와 같은 식을 linear regression에서는 MSE(Mean squared error) 평균제곱오차라고 한다. 꼭 알아야 하는 개념이므로 모른다면 유튜브를 검색해보는 것이 좋겠다고 할 수 있다.
지금부터는 위에서 theta번째 예측함수라고 했을 때 이게 뭔 말이냐 했던 분들만 보면 된다.
theta를 그냥 n번째라고 말해보겠다. 처음의 random함수를 사용하여 y= ax+b라는 함수에 대해서 a와 b를 랜덤하게 특정하여 함수를 만들어보자. 이때의 랜덤으로 생성된 a와 b가 각각 0.5와 2라고 해보자. 그럼 우리는 첫 번째 예측함수에 대해서 y=0.5x+2라고 할 수 있다.
그럼 실제로 우리가 train하는 데이터에 (x,y)= (1,3)이라고 했을 때 예측함수가 반환하는 예측 값은 0.5*1 +2 = 2.5이고 실제 값은 3이므로 loss(손실)은 0.5이다. 이러한 n개의 sample 모두 넣어서 loss값을 합하여 평균을 낸 값이 MSE이이다. 이렇게 까지 얘기 해줬는데 못알아 들을 수 있다. 유튜브를 이용해는 것이 좋을 것이다. ! 화이팅 !