11. pandas DataFrame -row, slicing(loc, iloc)
앞에서 DataFrame에서 대괄호 연산이 그 값을 column명으로 받는다는 것에 대해 공부했다.
때문에 DataFrame에서는 row을 불러오기 위해 loc, iloc 속성을 사용해야 한다.
그 전에 DataFrame에서의 slicing에 대해 알아보자.
DataFrame에서는 [] 대괄호 연산자가 column을 선택하지만, slicing을 하면 row레벨을 그대로 지원한다.
# <in>
import numpy as np
import pandas as pd
train_data = pd.read_csv('./train.csv')
train_data[7:10]
대괄호 연산이 slicing의 경우 column이 아닌 row를 지원하는 것을 확인할 수 있다.
이제 본격적으로 row을 선택해 명시된 row만을 출력하는 방법에 대해 알아보자.
- row selection
numpy Series나 python list의 경우 []대괄호로 row 선택이 가능하나, DataFrame의 경우는 기본적으로 column을 선택하도록 설계되어 있다.
때문에 DataFrame에서는 DataFrame의 .loc, .iloc 속성을 사용해 row를 선택할 수 있다.
loc는 DataFrame이 가지고 있는 인덱스명 그대로를 입력해 값을 출력하는 속성이고
iloc는 DataFrame이 가지고 있는 인덱스명이 아닌 DataFrame의 순서로 구성되어있는 0-based index명을 통해 값을 출력한다.
이 두 함수에서 ,를 사용하면 column도 선택이 가능하다.
우선 info()함수를 사용해 data의 정보를 파악해보자.
# <in>
train_data.info()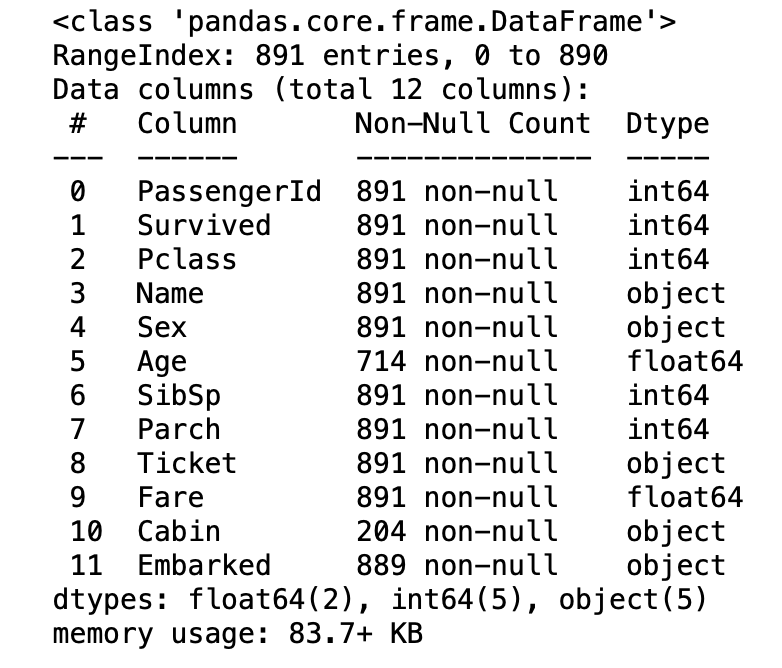
data의 index number가 0~890, 인덱스의 개수가 총 891개인 것을 확인할 수 있다.
이렇게 애초에 인덱스명이 0-based index라면 .loc함수와 .iloc함수의 결과가 크게 다르지 않다.
때문에 인덱스명을 다르게 바꾸어 loc와 iloc함수의 다른 점을 파악해보겠다.
# <in>
train_data.index = np.arange(100,991)
train_data.tail()
index함수에 새로운 인덱스 리스트를 주어 DataFrame의 인덱스명을 0-based index와 다르게 변갱해 보았다.
이제 loc, iloc를 비교해보자.
.loc[ ] 함수
loc함수는 기존에 존재하는 인덱스명을 가지고 데이터를 불러오는 함수이다.
# <in>
train_data.loc[986]
이와 같이 loc함수는 DataFrame에 존재하는 index명을 찾아 불러온다.
단일값의 경우 역시 series type을 반환한다.
# <in>
train_data.loc[[986, 100, 110, 990]]
부를 인덱스가 multiple한 경우 series type이 아닌 DataFrame type을 반환한다.
이번엔 iloc함수를 사용해보자.
iloc[ ] 함수
i.loc함수는 기존에 존재하는 인덱스명이 아닌 0-based index를 가지고 데이터를 불러오는 함수이다.
즉 기존에 index로 갖고 있는 고유값이 있더라도 DataFrame이 구성되어 있는 순서 index number(0-based index)를 통해 값을 불러온다는 것이다.
# <in>
train_data.iloc[[0, 100, 200, 2]] # 어떤 인덱스인지 상관없이 명시한 순번에 맞는 데이터를 가져오고 싶을 때
기존의 인덱스명과는 관계없이 순번과 관계되는 결과값들이 반환되는 것을 확인할 수 있다.
- row, column 동시에 선택하기
loc, iloc 속성에서 ,를 활용하여 row와 column을 동시에 명시하여 데이터를 부를 수 있다.
# <in>
train_data.loc[[986, 100, 110, 990], ['Survived', 'Name', 'Sex', 'Age']]
train_data.iloc[[101, 100, 200, 102], [1, 4, 5]]
# 앞: index명
# 뒤: column명
