15. pandas DataFrame NaN 데이터 전처리
DataFrame에서는 여러가지 이유로 NaN(결측값)이 발생할 수 있다. 데이터의 누락이나 처음부터 원래 데이터가 없는 경우라던가.
앞서 배웠듯이, NaN는 값이 0이라는 것이 아닌 값 자체가 없다는 것을 의미한다.
이런 데이터의 전처리 방법은 값이 없는 것을 무시하는 방법, 값을 다른 값으로 채워 대체하는 방법 크게 두 가지로 나눌 수 있다.
오늘은 이 두 가지 방법에 대해서 공부해 보도록 하자.
우선 .info()함수를 통해 데이터에 결측치가 존재하는 지 확인할 수 있다.
# <in>
import pandas as pd
train_data = pd.read_csv('./train.csv')
train_data.info()
info를 보면 다른 변수들은 891개로 결측값이 없지만, Age와 Cabin,Embarked는 데이터 누실이 있는 것을 확인할 수 있다.
이런 결측치를 찾는 또 다른 방법은로는 isna()함수가 있다.
isna()
# <in>
train_data.isna()
isna()함수를 사용하면 동일한 DataFrame 사이즈의 boolean DataFrame이 형성되는데 이 값이 True이면 NaN이다.
# <in>
train_data['Age'].isna()
대괄호를 활용하여 특정 column에 대해서 isna()함수를 사용할 수도 있다.
지금까지 DataFrame에 NaN value가 있는지 확인하는 방법에 대해 공부했다. 이제 이 NaN value를 처리하는 방법에 대해서 공부해보자.
우선 데이터를 삭제하는 방법이다.
# <in>
train_data.dropna()
기본적으로 dropna는 row기반으로 동작을 한다. 전체적인 레벨에서 특정 row에 NaN이 하나라도 있다면 해당 row을 drop시킨다.
.dropna() 함수에는 subset이라는 parameter가 존재한다.

# <in>
train_data.dropna(subset = ['Age'])subset parmeter의 경우 특정 column을 select하여, 다른 columns에 NaN 값이 없더라도 특정한 column에만 NaN가 없으면 row를drop하지 않도록 한다. muliple selection을 위해서는 별도로 묶을 필요 없이 ,를 이용하면 된다.
# <in>
train_data.dropna(subset = ['Age','Cabin])지금까지는 row level(행 레벨)로 지우는 방법이였다.
전체 row 중 하나라도 value 값에 NaN이 있다면 해당 column을 통으로 날려버리는 방법도 있다. .dropna()함수의 axis라는 parameter를 사용하면 된다. dropna의 default axis 값은 0(행)이다.
axis 값을 1(열)로 주고 dropna를 실행해보자.
# <in>
train_data.dropna(axis = 1)
NaN이 존재하는 row는 그대로고 column이 통째로 날아간 것을 확인할 수 있다.
두번째는 NaN값을 대체하는 방법이다.
이번 시간에는 NaN값을 평균값과 생존자/사망자 별 평균으로 대체하는 것으로 실습을 진행해 보겠다.
우선 'Age' 데이터의 평균값을 구해보자.
# <in>
train_data['Age'].mean()
# <out>
29.69911764705882그럼 이 값을 그대로
# <in>
train_data['Age'].fillna(train_data['Age'].mean())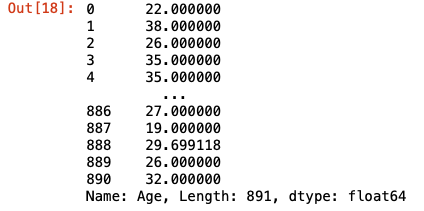
888번째에 NaN값이 평균값으로 대체된 것을 확인할 수 있다.
여기서 바꾼 데이터를 원본에도 적용하고 싶다면 전에 배웠던 parameter inplace를 True값로 설정하면 된다.
# <in>
train_data['Age'].fillna(train_data['Age'].mean(), inplace = True)

누락된 값이 있었던 Age의 데이터 개수가 891개로 수정된 것을 확인할 수 있다.
이제 생존자와 사망자를 구분하여 각각의 평균을 구해 대체해보자.
# <in>
# 생존자 평균
mean1 = train_data[train_data['Survived'] == 1]['Age'].mean()
# 사망자 평균
mean0 = train_data[train_data['Survived'] == 0]['Age'].mean()
# <out>
28.343689655172412
30.626179245283016
# <in>
train_data[train_data['Survived'] == 1]['Age'].fillna(mean1)
train_data[train_data['Survived'] == 0]['Age'].fillna(mean0).fillna() 함수를 사용하여 NaN값에 각각의 평균값을 대체해준다. 하지만 이는 원본에는 영향을 주지 않는다. 원본 DataFrame에 이들을 넣어주어야 임무가 완료되는데.. 나는 .loc함수를 사용해보겠다.
# <in>
train_data.loc[train_data['Survived'] == 1, 'Age']
train_data.loc[train_data['Survived'] == 0, 'Age']
# <out>loc함수에 boolean 값과 column값 'Age'를 넣었을 때 반환되는 값은 fillna() 함수를 사용해 반환된 Series값의 shape과 동일한 것을 확인할 수 있다. 때문에 그 값을 그대로 train_data value값에 넣어 수정해주면 된다.
# <in>
train_data.loc[train_data['Survived'] == 1, 'Age'] = train_data[train_data['Survived'] == 1]['Age'].fillna(mean1)
train_data.loc[train_data['Survived'] == 0, 'Age'] = train_data[train_data['Survived'] == 0]['Age'].fillna(mean0)
# <out>'Age' Column value에 NaN값이 있는 지 확인해보자.


'Age' column에 NaN값이 사라진 것을 확인할 수 있다. 그럼 이제 생존자, 사망자 별 평균에 맞게 결측값이 대체됐는 지 확인해보자.
이 전에 구했던 생존자의 평균 연령은 각각 28.343689655172412세 , 30.626179245283016세 였다.
# <in>
train_data.loc[train_data['Age'] == 28.343689655172412, 'Survived'] == 1
train_data.loc[train_data['Age'] == 30.626179245283016, 'Survived'] == 0두 boolean Series 값이 모두 True를 원소를 갖는 것이 확인되면 결측값이 알맞게 대치된 것이다.
끝