16. pandas DataFrame - 숫자형, 범주형 데이터의 이해
모든 data에는 type이 존재한다.
DataFrame에서는 각 column이 가지고 있는 value의 type을 info()함수를 사용해 확인할 수 있다.
# <in>
train_data = pd.read_csv('./train.csv')
train_data.info()
반환된 값을 통해 승객id, 생존여부 등은 int(정수) type, 이름이나 성별은 obj type... 각 value의 data type을 확인할 수 있다.
이러한 데이터 타입을 분류할 수 있는 두 가지 분류법이 있는데, 바로 데이터를 숫자형 데이터와 범주형 데이터로 구분하는 방법이다.
1. 숫자형 데이터 (Numerical Type)
- 숫자형 데이터란 연속성을 띄는 숫자로 이루어진 데이터이다. 이를 테면 연령 데이터나 요금 데이터처럼 값이 연속성을 띄는 데이터가 숫자형 데이터이다.
2. 범주형 데이터 (Categorical Type)
- 연속적이지 않은 값(대부분의 경우 숫자를 제외한 나머지 값)을 갖는 데이터를 의미한다. 예를 들어 이름, 성별 데이터가 있다.
- 어떤 경우엔 숫자형 타입이라 할지라도 개념적으론 범주형으로 데이터처리를 해야 하는 경우가 있는데, 우리의 DataFrame에선 Pclass나 Survived 데이터로 그 예시가 된다.
Pclass와 Survived 데이터는 숫자형이지만, 모두 어느 특정 범주 안에 있는 값으로만 이루어진 데이터이다.
숫자형 데이터를 범주형 데이터로 바꿔보자.
3. astype() 함수 - 숫자형 데이터 - > 범주형 데이터화
# <in>
train_data['Pclass'] = train_data['Pclass'].astype(str)
위에서 int type이었던 Pclass의 type이 astype()함수를 통해 object로 바뀐 것을 확인할 수 있다.
이번엔 Age 데이터를 범주형 데이터로 만들어보자.
Age 데이터는 숫자형 데이터 그대로도 사용이 가능하지만, 범주형 분석을 하는 경우를 대비해 한 번 바꿔 보도록 하겠다.
27.0 -> 20대, 38.0 ->30대 로 바꿔보는 과정에 for문 등 반복문을 사용하는 것도 가능하지만, numpy나 pandas에서는 내장된 특성을 잘 활용하여 이러한 loop style을 지양 할 수 있다.
우선 나이를 범주형으로 만드는 함수를 만들어보자.
# <in>
import math
def age_categorize(age):
if math.isnan(aga):
return -1
return math.floor(age / 10) * 10
# math 라이브러리에 floor 함수를 사용하여 소수점을 없애줄 수 있다.
# math 라이버르러에 isnan 함수를 사용하여 NaN값을 찾을 수 있다.원래 같으면 for문을 돌리겠지만 DataFrame의 apply()함수를 사용할 수 있다.
4. apply()함수
- 변환 로직을 함수로 만든 후,
apply()함수를 사용해 적용이 가능하다.
# <in>
train_data['Age'].apply(age_categorize)
Age column의 value 값들이 알맞게 범주형 데이터화 되었다.
5. 범주형 데이터 전처리
기본적으로 범주형 데이터의 경우는 연산이 불가능하다. 때문에 연산처리가 가능하도록 숫자 데이터로 바꿔줘야 하는 경우가 있다.
예제로 공부해보자.
# <in>
import pandas as pd
train_data = pd.read_csv('./train.csv')
train_data.head()
범주형 데이터를 전처리하는 방법 중 One-hot encoding 방법을 공부해보자.
-One-hot encoding
- 범주형 데이터는 분석단계에서 계산이 어렵기 때문에 숫자형으로 변경이 필요하다.
- 범주형 데이터의 각 범주(category)를 column레벨로 변경이 가능한데
- 해당 범주에 해당하면 1, 아니면 0으로 채우는 인코딩 기법이다.
- pandas.get_dummies 함수를 사용할 수 있다.
- drop_first (parameter): 첫번째 카테고리 값은 사용하지 않는다.
- pd.get_dummies()
# <in>
pd.get_dummies(train_data)
dummies함수가 반환한 결과를 보면 각각의 모든 Name을 column level로 올린 것 처럼 보인다. 왜냐하면 Name은 object type이기 때문이다.
동일한 object type의 Cabin도 마찬가지다. 즉 dummies함수는 모든 object형, 숫자가 아닌 형식을 이런식으로 바꿔버린다.
dummies 함수의 parmeter에는 columns가 있다. 특정 columns만을 명시하여 범주화할 수 있다.
# <in>
pd.get_dummies(train_data, columns = ['Pclass','Sex','Embarked'])
Pclass의 등급, 성별의 종류가 모두 하이푼 아래에 column레벨로 변경 되었다.
또 다른 parmeter drop_first는 변수를 하나라도 줄이기 위해서 사용되는 parameter인데 사용한 것과 사용하지 않은 반환값을 비교해 그 쓰임을 느껴보자.

drop_first =False 한 결과값은 Pclass1, 2, 3 모두 존재한다.
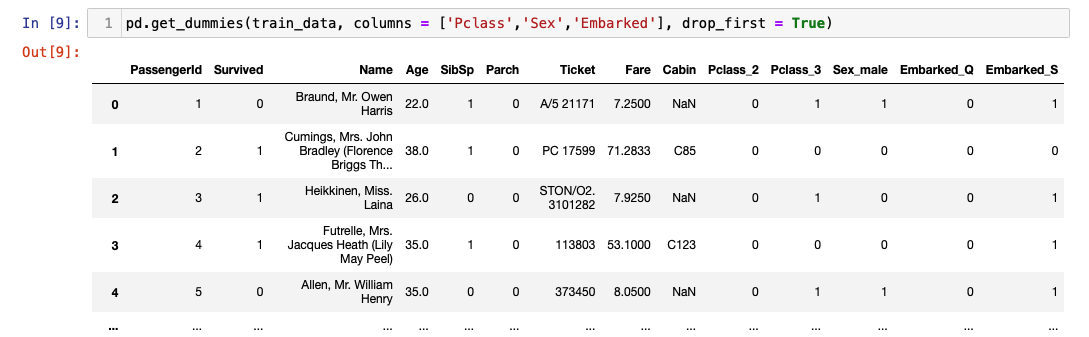
drop_first = True의 결과값은 첫 번째 값은 존재 하지 않는다. 때문에 Pclass2와 3가 모두 0인 row는 Pclass 1인 것으로 유추할 수 있다.
drop_first paramter를 사용하면 불필요한 변수를 줄일 수 있다. 때문에 일반적으로 dummies함수를 사용할 때 drop_first paramter 에 True값을 준다.