17. pandas DataFrame - groupby
group by란.
- 아래의 세 단계를 적용하여 데이터를 그룹화하는 것이다.
- SQL의 group by와 개념적으로는 동일하고, 사용법은 유사하다.
1. 데이터 분할
2. operation 적용
3. 데이터 병합
# <in>
import pandas as dp
import numpy as np
df = pd.read_csv('./train.csv')
df.head()
groupby()함수를 사용해 특정 column을 그룹화하는 것은 객체만이 반환 될 뿐, 큰 의미를 갖지는 않는다.
groupby()의 groups속성을 활용해서 그룹에 속한 index를 dict형태로 표현할 수 있다.
말로만 하면 이해가 잘 되지 않으니 실습으로 공부해보자.
# <in>
class_group = df.groupby('Pclass')
# <in>
class_group = df.groupby('Pclass')
class_group.groups
groups속성을 통해 DataFrame의 Pclass열이 dict로 표현된 것을 확인할 수 있다. 실제 column의 value값들이 index값이 됐고, DataFrame의 index값은 value값으로 표기됐다.
이해를 쉽게 하기 위해, 더 적은 범주를 가지고 있는 카테고리인 성별로 groupby한 결과도 확인해보자.
# <in>
gender_group = df.groupby('Sex')
gender_group.groups
DataFrame의 Sex column의 value값인 female, male 값이 dict의 index(key)값으로, DataFrame의 index값은 dict의 value값으로 들어가 표기된 것을 확인할 수 있다.
이제 이렇게 groupby를 통해 반환된 group data에 적용 가능한 통계 함수(NaN은 제외하여 연산)에 대해서 공부해보자.
groupping 함수란
- 그룹 데이터에 적용 가능한 통계 함수로
- NaN값은 연산에서 제외한다.
- count - 데이터의 개수
- sum - 데이터의 합
- mean, std, var - 평균, 표준편차, 분산
- min, max - 최소, 최대값
실습을 통해 공부해보자.
- group.count()
# <in>
class_group = df.groupby('Pclass')
class_group.count()

group 데이터에 .count()함수를 사용하면 해당 value를 갖는 데이터를 기준으로 data count를 구해 DataFrame으로 반환해준다.
- group.mean()
# <in>
class_group.mean()
Pclass별 column들의 평균을 보여준다. 여기서 id같은 value 평균은 의미가 없다. 이런 경우 특정 값을 지정해서 Pclass별 평균을 확인할 수도 있다.
# <in>
class_group.mean()['Survived']
Survived column 만 지정해서 결과를 보면 Pclass별 생존율을 확인할 수 있다.
-group.min(), max()
Pclass별 각 column의 최솟값 최댓값도 확인할 수 있다.
# <in>
class_group.min()
마찬가지로 passengerid의 최솟값은 큰 의미를 갖지 않는다. 때문에 이번엔 Age column을 특정해보겠다.
# <in>
class_group.min()['Age']
여기서 소숫점 값은 아마 갓난 아이(1년이 채 되지 않은)의 나이를 의미하는 것으로 보인다.
같은 방법으로 최댓값도 볼 수 있다.
# <in>
class_group.max()
이번엔 복수 columns로 groupping을 해보자.
복수의 columns으로 groupping을 하기 위해서는 단순히 groupby 안에 column리스트를 전달하면 된다.
복수의 columns로 groupping된 group data의 통계함수를 적용한 결과는 multi index를 갖는 dataframe으로 반환된다.
클래스와 성별에 따른 생존율을 구해보자.
# <in>
df.groupby(['Pclass','Sex']).mean()['Survived']
pclass 1의 female은 생존율이 가장 높았고, pclass 3의 male의 생존율이 가장 낮았다.
앞서 group data의 통계함수를 적용한 결과는 DataFrame으로 반환된다고 공부했다. 때문에 loc함수를 사용해 multi index DataFrame인 통계 결과에 index를 특정해 데이터를 반환해 볼 수 있다.
# <in>
df.groupby(['Pclass','Sex']).mean().loc[(2, 'female')]

# <in>
df.groupby(['Pclass','Sex']).mean().loc[(2, 'female')]['Survived']
- index를 이용한 group by
index가 있는 경우, groupy 함수에 level을 사용 가능하다. level은 index의 depth를 의미하며, 가장 왼쪽부터 0부터 증가한다.
set_index() 함수
- column data를 index레벨로 변경한다.
reset_index() 함수
- 인덱스를 초기화한다.
set_index()함수를 사용해서 Pclass를 인덱스로 column으로 지정해보자.
# <in>
df.set_index('Pclass')
# <in>
df.set_index(['Sex','Pclass'])

리스트로 index를 주면 muliti index를 가질 수도 있다.
다시 index를 본래 DataFrame 그대로 초기화하자.
# <in>
df.set_index(['Pclass','Sex']).reset_index().set_index() 함수 역시 원본 데이터에는 영향을 주지 않기 때문에 복사본 data 값에 reset_index()를 해야 그 의미를 갖는다.
# <in>
df.set_index(['Age','Pclass']).groupby(level = 0).mean()
여기서 groupby의 level parameter의 개념이 나오는데 왼쪽부터 0이라는 의미는 가장 왼쪽의 index column 'Age'를 의미한다.
level = 1 로 parameter를 준다면 Pclass 기준으로 평균을 제공할 것이다.

나이대별 생존율 구하기
우선 위에서 생성한 숫자형 연속형 데이터인 Age 데이터를 범주화하는 함수를 불러보자.
# <in>
import math
def age_categorize(age):
if math.isnan(age):
return -1
return math.floor(age / 10) * 10# <in>
df.set_index('Age').groupby(age_categorize).mean()['Survived']
- aggregate(집계) 함수 사용하기
- groupby 결과에 집계함수를 적용하여 그룹별 데이터 확인이 가능하다.
# <in>
df.set_index(['Pclass','Sex']).groupby(level = [0, 1]).aggregate([np.mean, np.sum, np.max])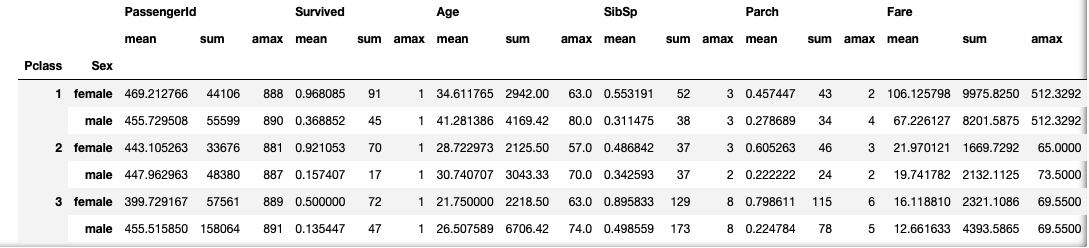
# <in>
df.set_index(['Pclass', 'Sex']).groupby(level=[0, 1]).aggregate([np.mean, np.sum, np.max])['Survived']